Back in 2021 I wrote about dynamic CSS color themes with similar
contrasts,
where I used a SCSS function to automatically adjust colors to meet the WCAG
7:1 contrast ratio against both a light and a dark background. The idea was
that you specify the intent — the hue you want — and the build system derives
the actual color that achieves sufficient contrast.
That worked well, but it required dart-sass. Hugo’s built-in LibSass was
removed in Hugo 0.128, leaving dart-sass as the only SCSS transpiler. Getting
dart-sass into the Nix build required a symlinkJoin bundle that wrapped Hugo
with dart-sass on its PATH — not terrible, but an extra moving part in both
devshell.nix and packages/default.nix.
At the end of that post I briefly mentioned that I configured remote unlocking
of my encrypted ZFS pools over SSH on boot, linking off to the NixOS wiki. The
wiki page is now quite outdated and the approach it describes no longer works
well with modern NixOS, which uses a systemd-based initrd by default. This post
covers the current way to do it.
I have been focused lately on trying to resolve relocation overflows when compiling large binaries in the small & medium code-models.
Often when talking to others about the problem, they are quick to offer the idea of using the large code-model.
small code-model
Assumes all code and data comfortably fit within a single 2GiB window. The compiler relies on fast, compact 32-bit PC-relative offsets for all function calls and data accesses.
medium code-model
Assumes code stays under 2GiB, but data might exceed it. It splits data into “small” and “large” sections using 32-bit offsets for code and small data, and generating 64-bit addresses strictly for the large data.
large code-model
Makes zero assumptions about size or placement, lifting the 2GiB limit entirely. The compiler is forced to use 64-bit absolute addressing for every external reference.
Despite the performance downsides of using the large code-model from the instructions generated, it’s true that its intent was to support arbitrarily large binaries.
However does anyone actually use it?
Turns out that large binaries do not only affect the instructions generated in the .text section but may also have effects on other sections within the ELF file such as
.eh_frame (exception handling information), .eh_frame_hdr (optimized binary search table for .eh_frame), and even .gcc_except_table.
Let’s take .eh_frame and .eh_frame_hdr as an example. They specifically allow various encodings for the data within them (sdata4 or sdata8 for 4 bytes and 8 bytes respectively) irrespective of the code-model used. However, it looks like the userland has terrible support for it!
If we look at the .eh_frame_hdr format, we can see how these encodings are applied in practice. The encoded entries in this column are the ones that actually resolve to specific DWARF exception header encoding formats (like sdata4, sdata8, udata4, etc.) depending on the values provided in the preceding *_enc fields.
Note: The encoded values for eh_frame_ptr and fde_count dictate their byte size and format. For example, if fde_count_enc is set to DW_EH_PE_sdata4, the fde_count field will be processed as an sdata4 (signed 4-byte) value.
Up until very recently (pull#179089), LLVM’s linker lld would crash if it tried to link exception data (.eh_frame_hdr) beyond 2GiB.
This section is always generated to help stack searching algorithms avoid linear search.
Once we fix that though, it looks like libgcc (gcc-patch@) and libunwind (pull#964) explicitly either crash on sdata8 or avoid the binary search table completely reverting back to linear search.
How devasting is linear search here?
If you have a lot of exceptions, which you theoretically might for the large code-model, I had benchmarks that started at ~13s improve to ~18ms for a ~700x speedup.
Other fun failure modes that exist:
Thread Local Storage (.tdata and .tbss)
Highly optimized TLS access models often rely on 32-bit offsets from the thread pointer to fetch thread-local variables. Massive binaries can push these variables too far away, breaking the fast-path TLS instructions and forcing you into slower, more general TLS models.
The String Table (.strtab)
Even in a 64-bit ELF (Elf64_Sym), the st_name field, which holds the offset to the symbol’s name in the string table is only a 32-bit integer. If you have enough heavily mangled C++ templates, your string table can theoretically hit the 4GiB limit, at which point the ELF format itself fundamentally caps out. 🫠
It seems like the large code-model “exists” but no one is using it for it’s intended purpose which was to build large binaries.
I am working to make massive binaries possible without the large code-model while retaining much of the performance characteristics of the small code-model.
You can read more about it in x86-64-abi google-group where I have also posted an RFC.
I closed that post with the following, and we're going to expand on it:
The real question, however, is trust. I'm not saying that the Chinese models are dodgy. It's more of a meta question. You see, the question of trust extends to the frontier labs as well. As we enter this weird new space where businesses are being automated with AI, it essentially hands over your business's operations to another entity.
Another question on my mind is what happens to a country that lacks AI capabilities? When their businesses depend upon AI, and thus the country's economy depends upon AI, what happens if the spigot ever gets turned off through sanctions or war?
If we zoom forward a couple of years. It's now the future, and the future is undefined because no one really knows what it will look like, because it is the future, but if we play with the notion of extrapolating trends that are just starting right now, where founders, including myself, are building businesses with a mindset of autonomous software and product factories. We will soon be in a place where businesses are highly dependent upon the capabilities of AI, whether that be in access or how the models function.
This concerns me greatly, and it extends far beyond business and into society itself. You see, right now, society is already going through a Harry Potter-style sorting hat event where people are picking and choosing which tribe they belong to.
If you use any of the Frontier Lab models enough, you develop an eye for their tendencies, how they write, how they think, and how they communicate. If people are picking a single AI producer and using that AI daily in their day-to-day life to make decisions, they are outsourcing their cognitive security to someone else.
What concerns me is that, almost three or four years ago, Anthropic conducted research that allowed Frontier Labs to perform laparoscopic keyhole surgery to change how the models perform after they were made. This experiment was called Golden Gate Claude.
In this experiment, Anthropic performed surgery on the model's weight dimensions for the Golden Gate Bridge and no matter what you did when you were having a conversation with this model, the Golden Gate Bridge was always top of mind for the model.
For example, let's say that you wanted to go get some Panadol. It would give you driving instructions to a pharmacy via the Golden Gate Bridge. If you wanted to write a poem, that poem would prominently feature the Golden Gate Bridge.
Through modification of the model weights, the Golden Gate Bridge became a black hole where you could not escape from the gravity of the Golden Gate Bridge.
I'm surprised most people don't even know that this research exists and haven't really talked about or even written about what it could mean for society in the future.
Here's a scenario for you to chew on:
What happens when, in a couple of years, if a famous web search company, which was also a frontier AI lab, retires ads in their search product and instead offers their advertisers the ability to bid on the ability to rank higher in model weights than the competitors?
Most people would never know because they've outsourced their cognitive capability to a model.
What happens is if a famous social media network, which is also a Frontier lab, starts allowing their advertisers, to similarly bid to rank higher in the model weights, of their open source models that they're releasing for free.
Now, what happens if you extrapolate this? I don't know if this will actually happen. It's just baseless speculation, but one thing is for sure: we're entering into this world where a select few companies, these frontier labs, will have significant power over the world and how society functions, thinks and operates.
If these topics concern you, then perhaps the only true solution is that you should raise your own model, because by doing so, you gain the ability to protect your own cognitive security, business operations and supply chain.
People often ask me how I feel about open-source models, and to be clear, I'm very supportive of them. But I can't help pondering about the following...
Open source always was and always will be a financial weapon by design. You see, one of the primary goals of open source was by releasing something as free, it removes the ability to make money from it.
Now, I'm not sure how old you are, dear reader, but if you wind the clock back far enough, you'll find traces in history that support this claim. Heck, you're probably even using Linux right now on a computer, in your house or at a server in a data centre. This was not always true. Back when this war was last raging, back in 1998, Windows was the server operating system of choice.
Linux was created to destroy Microsoft's ability to make money from Microsoft Windows. The same holds true for OpenOffice vs. Microsoft Office. It's now almost 20 years since the Halloween papers. If you're not familiar with the topic, I suggest you dig in and get up to speed with the subject matter.
In the last week of October 1998, a confidential Microsoft memorandum on Redmond's strategy against Linux and Open Source software was leaked to me by a source who shall remain nameless. I annotated this memorandum with explanation and commentary over Halloween Weekend and released it to the national press. Microsoft was forced to acknowledge its authenticity. The press rightly treated it as a major story and covered it (with varying degrees of cluefulness). - https://en.wikipedia.org/wiki/Halloween_documents
Now you might be wondering why I'm writing about this. It's because local models are getting good. Heck, local models these days tend to be two to four months behind the leading-edge frontier labs.
Here's the thing, though: these local models are being released for free. You can just download them, or pay a minuscule fee (circa $5 USD/month) to access Frontier's open-source models from Alibaba or Z.AI.
Meanwhile, America is dumping literally trillions of dollars into research at these frontier labs. Now, I'm not calling AI a bubble because this absolutely is ROI. At this stage, I think it's impossible for anyone to say it is a bubble.
What I hope to do through this blog post is tweak some people's thinking beyond the bubble narrative. Perhaps what we're seeing is history repeating itself, but perhaps it's a little more sinister. Now, my background is not in geopolitics. I can't help but wonder if the US economy backs itself so hard into a corner funding these research labs, and if these research labs receive a bailout, what does that mean for China? Why is China releasing these models for free?
Perhaps what we're seeing here is all-out economic warfare between one nation-state and another through the weaponisation of open source because open source was, is, and always will be a financial weapon. In history, free was previously used against companies, but, if my speculation is on the mark, this is the first time it has been used at the national level by one nation against another.
I don't know what this means, and I'll leave the commentary, whether true or false, to someone with expertise in this arena but if you're aware that this is happening, then there are many ways where you can benefit from what is happening.
If you are a student or your financial budget does not allow for dropping $1,000 a month for subscriptions from all the major labs, then you can use these open-source models.
If you're a business, you should build with the mindset that local inferencing will be a thing. I suspect that in a not-so-distant future, we will have local models where society has full visibility into what goes into their training data sets, truly open-source models that are end-to-end reproducible, and I'm excited about these possibilities.
The real question, however, is trust. I'm not saying that the Chinese models are dodgy. It's more of a meta question. You see, the question of trust extends to the frontier labs as well. As we enter this weird new space where businesses are being automated with AI, it essentially hands over your business's operations to another entity.
Another question on my mind is what happens to a country that lacks AI capabilities? When their businesses depend upon AI, and thus the country's economy depends upon AI, what happens if the spigot ever gets turned off through sanctions or war?
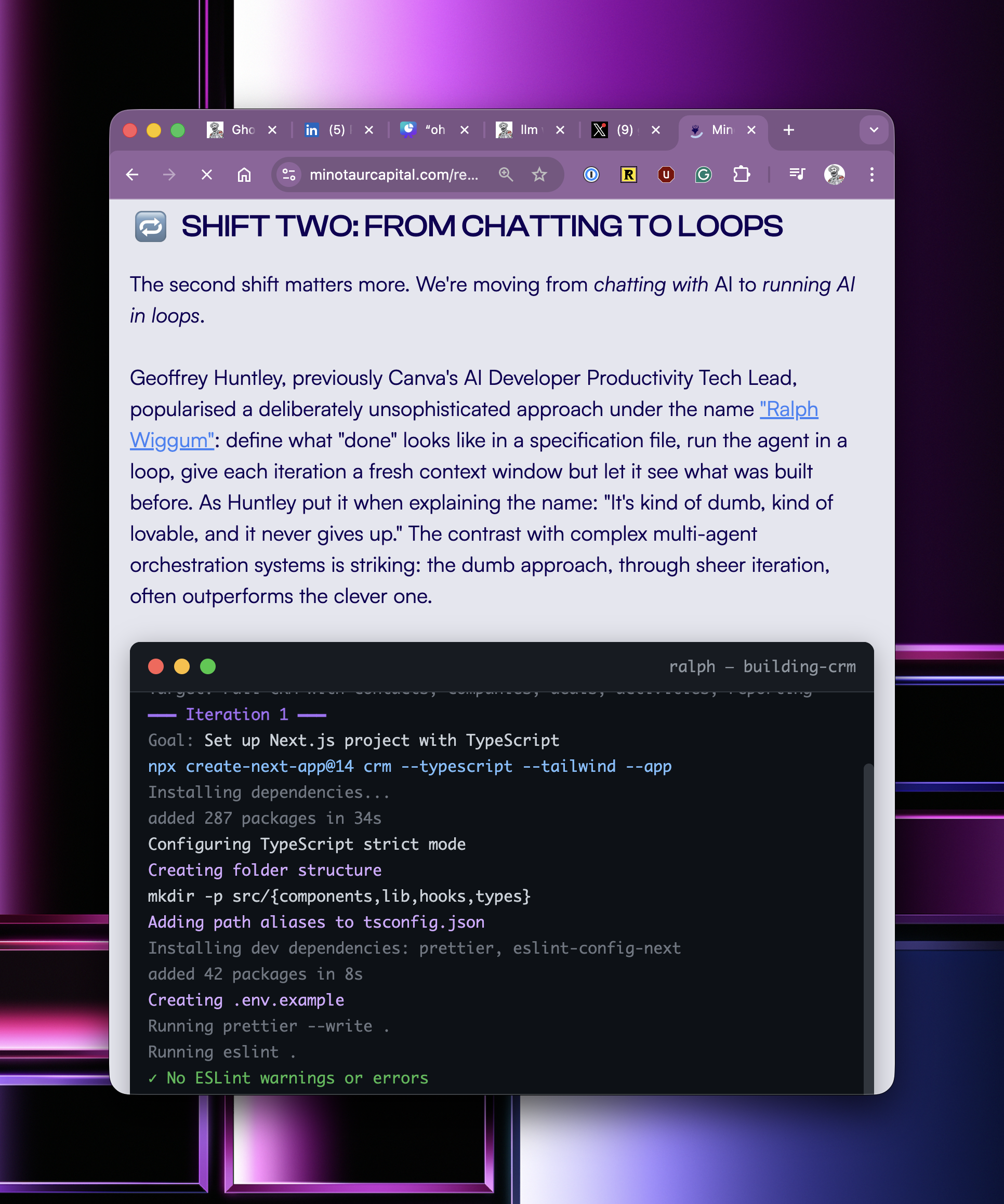
This one is short and sweet. if you want to port a codebase from one language to another here’s the approach:
Run a ralph loop which compresses all tests into /specs/.md which looks similar to “study every file in tests/* using separate subagents and document in /specs/*.md and link the implementation as citations in the specification“
Then do a separate Ralph loop for all product functionality - ensuring there’s citations to the specification. “study every file in src/* using seperate subagents per file and link the implementation as citations in the specification“
Once you have that - within the same repo run a Ralph loop to create a TODO file and then execute a classic ralph - doing just one thing and the most important thing per loop. Remind the agent that it can study the specifications and follow the citations to reference source code.
For best outcomes you wanna configure your target language to have strict compilation
The key theory here is usage of citations in the specifications which tease the file_read tool to study the original implementation during stage 3. Reducing stage 1 and stage 2 to specs is the precursor which transforms a code base into high level PRDs without coupling the implementation from the source language.
Below you'll find an AI transcription of everything we riffed about.
Key distinction: Software Development vs. Software Engineering:
Software development (typing code, prompting LLMs) is accelerating massively and becoming ubiquitous—anyone (e.g., a hairdresser using Cursor) can now be a "developer" due to abundant AI knowledge/tools.
Software engineering remains essential and is evolving: engineers now act like locomotive engineers — keeping the "train" on tracks by designing safe, reliable systems/automations rather than working "in" the business (manual coding).
Shift focus to designing loops, automations, safety mechanisms (e.g., sandboxing, credential management, security), risk engineering, and responsible AI utilization.
Implications for professionals:
If your identity is tied to being a traditional "software developer" (keyboard typing), it's a tough time—prompting for outcomes is the new norm.
If your employer bans AI tools, leave immediately: it's business suicide to ignore AI, while staying risks employability suicide as the market for manual coders shrinks rapidly.
Engineers should prioritize raw technical/cognitive skills → engineer away concerns (e.g., replace binary code reviews with risk-based approaches, feature flags, constrained blast radius, auto-migrations).
Open source is "dead" (or greatly diminished):
Traditional open-source libraries existed to ease hiring and sharing reusable code.
Now, with AI generation, there's little point: generating code avoids maintainer burnout, GitHub issue delays, abandoned projects, supply-chain attacks (e.g., npm takeovers), and Dependabot update toil.
Better to generate first-party code for faster evolution, full control, and no human "tool calls" (which disqualifies true AGI-like autonomy).
Exceptions: highly sensitive areas like PKI/SSL where generation isn't appropriate.
Broader industry shifts in an abundance era:
Software moves from scarcity (differentiated libraries, hard-to-replicate tech) to abundance (easy generation/reimplementation).
Many software products become hyper-commodity (like utilities: electricity, web hosting) — easily screenshot + reimplemented via AI (e.g., Claude).
Vendor lock-in and switching costs vanish (e.g., auto-migrating databases/apps).
True moats now lie in non-technical areas: contracts, relationships, handshakes, stakes, distribution, taste/judgment — the "hard things of business."
Unit economics of software have fundamentally changed → questions if software remains investable (VCs unsure about moats, fundraising challenges).
Future: hyper-personalized software; old models of building/scaling via scarcity are disrupted.
Closing advice
Stay relevant by running fast, staying curious, and adapting to the "brave new world."
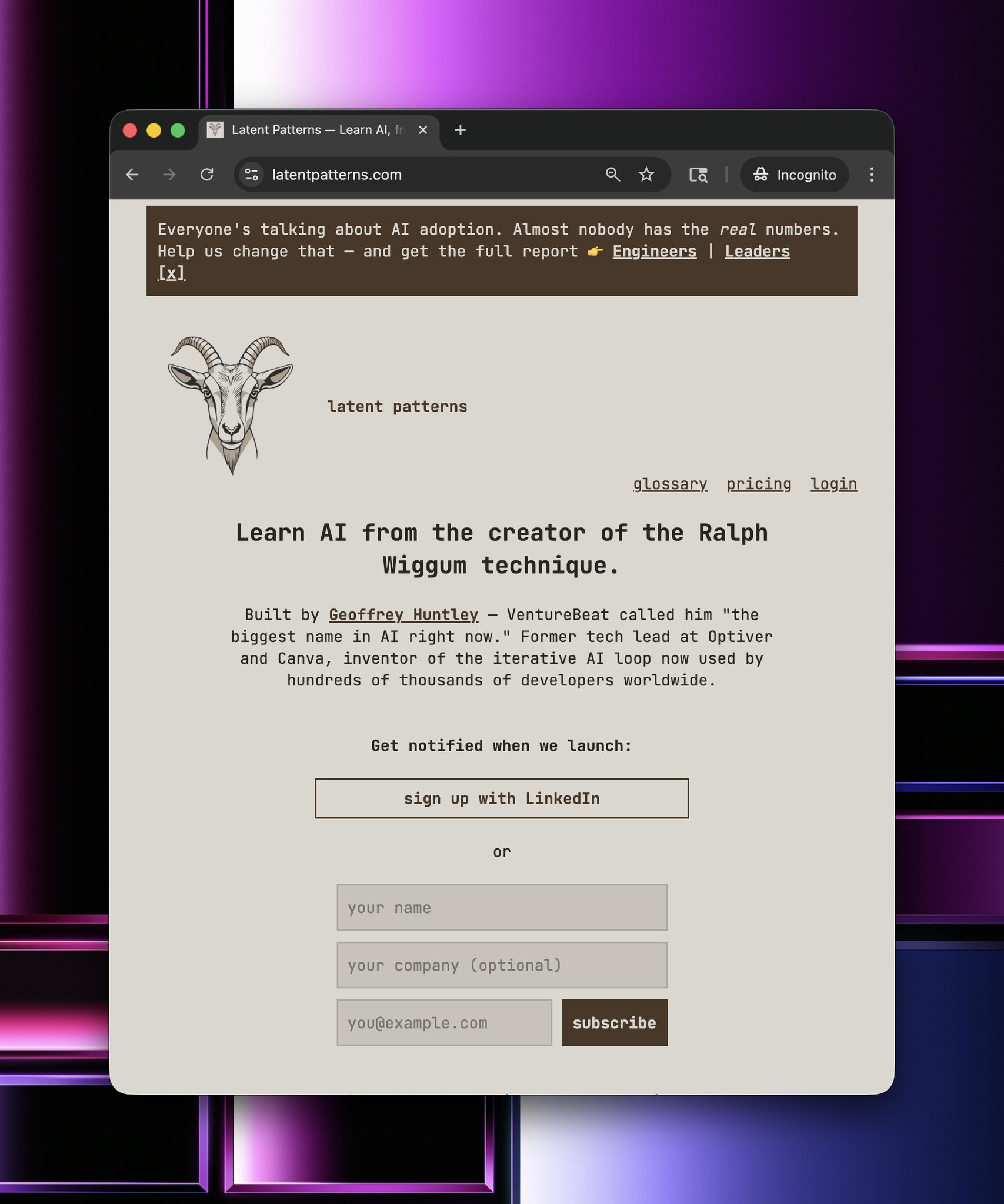
Hey folks, I'm currently over in SF. For the last couple of weeks, I've been cryptically tweeting about a hidden mode within something I've been building on called Latent Patterns (see below), and over the last couple of days, I've started opening up and showing people that I suspect is the (or a) future of what's to come.
An educational platform for learning AI concepts. No fluff, no filler. Just the concepts you need, explained clearly.
Latent Patterns builds Latent patterns. I've taken some of the ideas behind "The Weaving Loom" and inverted them, put them into the product itself and have perhaps accidentally created a better Lovable.
It's interesting because I see all these developer tooling companies building for the persona of developers, but to me, that persona no longer exists. You see, within latent patterns, the product (latent patterns) is now the IDE.
0:00
/0:33
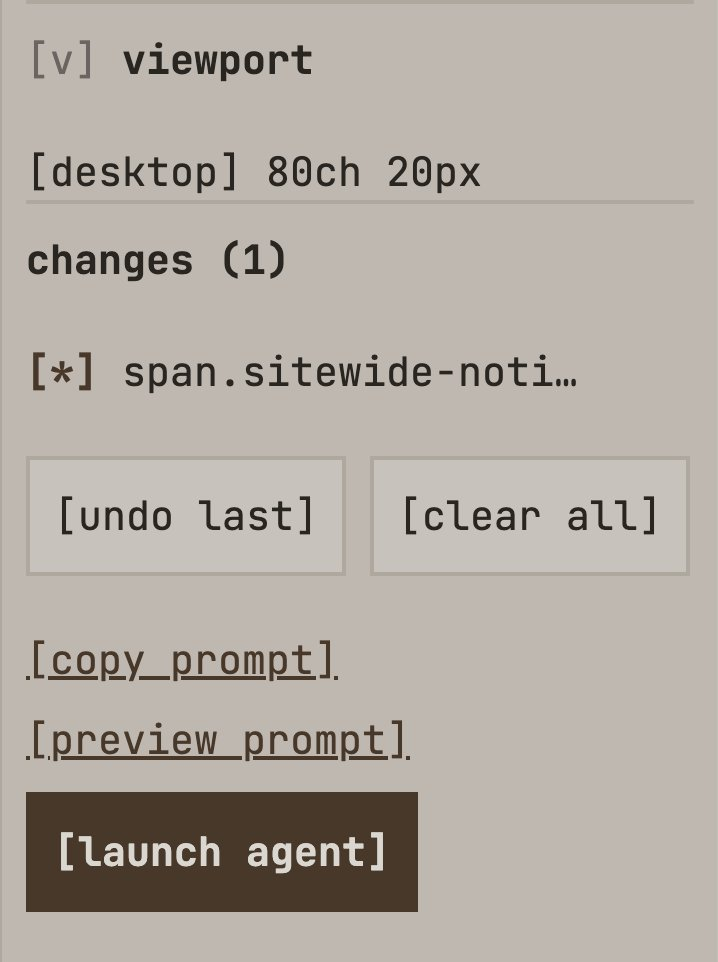
If I want to make a change to something, I pop on designer mode, and this allows me to develop LP in LP. I can make changes to the copy or completely change the application's functionality using the designer substrate directly from within the product, then click the launch agent to ship.
If I click Launch Agent, then it utilises Cursor's new Cloud Agents and Workflow Automations to ship it straight into production using a risk-based approach.
I guess you're wondering right now why I would not have my own agents for code editing? Well, that's because they're commodities now. Last month, Cursor hooked me up with a preview of their new stuff, and now that it's out, this is how I've been using it. You could do this with any background execution utility service.
Instead of having a manual code review for everything, I just ship it. If something is high enough on the risk matrix, for example, a database schema migration, then it halts the shipping, and I have to do a manual review. Having said that, I'll repeat something I've said again and again over the years. You need to watch the loops. Watch the inferencing because that's where your learning is at. When I want something built, I just open up my phone and watch the output get made. I'm supervising it. I'm on the loop, not in the loop.
Here's what the prompt roughly looks like. It depends on what the functionality has been changed, whether it's a content change or an actual application logic change.
I think we're entering into an era of hyper-personalised software, and our industry actually works in circles. The last time we had hyper-personalised software for business was Microsoft Access, Delphi and Visual Basic. You see, back in the year 2000, every business had hyper-personalised software.
They didn't have to bend or conform to someone else's product vision on how they should operate their business. They didn't need Zapier or all these workflow automation systems stitching together SaaS. No, they had rapid application development, and these businesses had hyper-personalised software.
So I've been playing around in this designer within LP, and I've got a rough technical prototype for how I might retire most developer practices, including CI/CD.
One thing that is irking me is how natural it seems for everyone to accept that we should wait until we see the outcome. This never used to be the case. Productivity with Microsoft Access back in 2000 was amazing.
Every second counts; even the 60 seconds for CI/CD deployments for LP, as it is now, is too long. So I'm starting to come to an understanding that the natural next step is to live-edit a program's memory and control flow. Sure, I could move content from the file system to the database, but we can do better. How can we kill CI/CD as it is today and instead safely live-edit the program's logic?
If you build with the mindset and awareness that inferencing speed will be near-instantaneous in the future, then it just makes sense that the logical destination is for anyone to be able to develop the product from within the product, and for the product to become the IDE itself.
All businesses need the following "widgets" / components:
Analytics
CRM
Support Desk
Newsletters
Meeting Scheduling
So, for the last couple of weeks, I've been doing some window shopping...
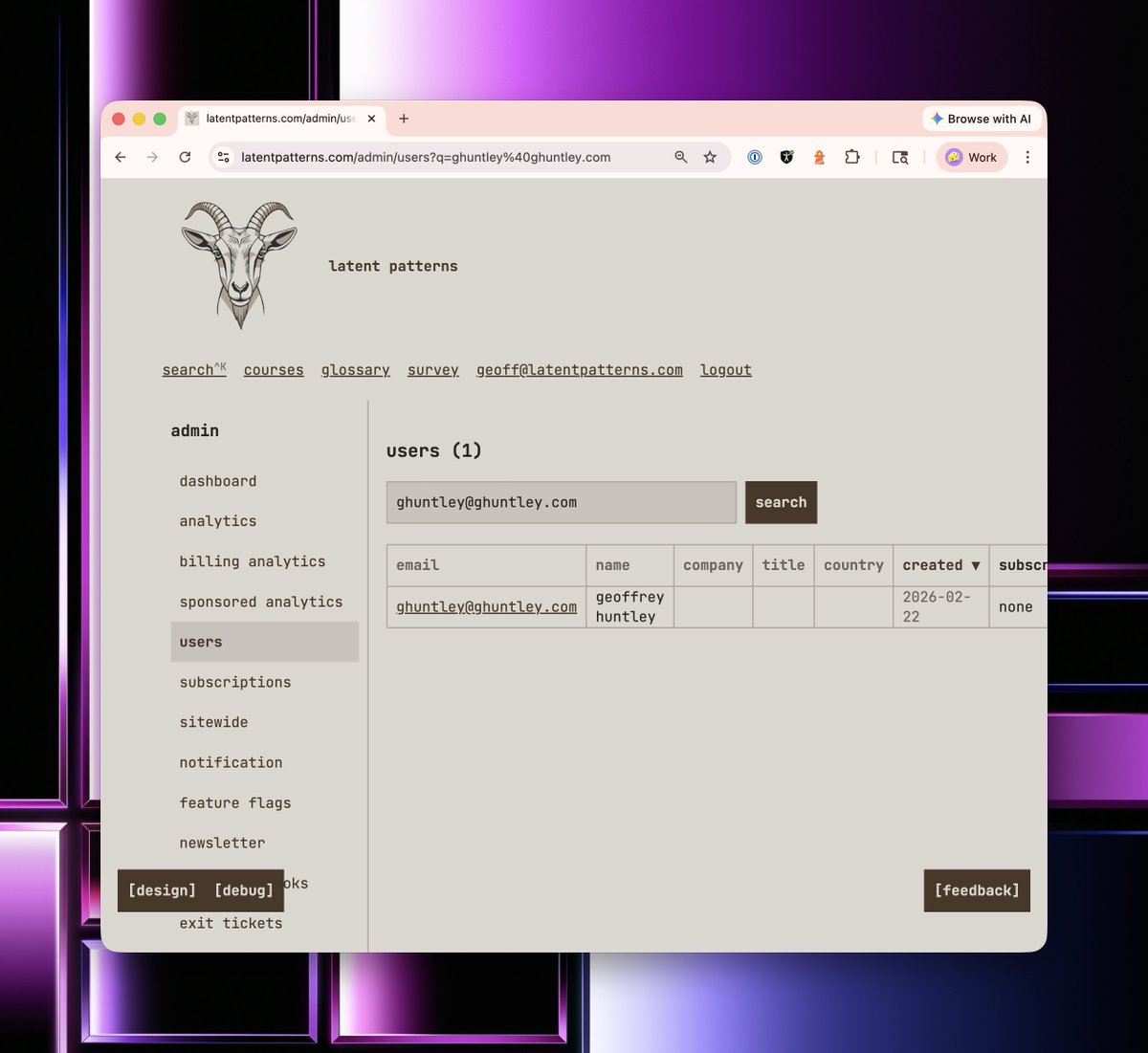
So the first thing I did was model the notion of a user and add customer management functionality. Consider how long it would take in traditional software developer to build such functionality. A very simple user management database with a front end. Before AI, this would have taken weeks at most corporations. Before our industry went backwards, this used to take seconds. Back in the year 2000, it used to be seconds. This used to be just Microsoft Access tables.
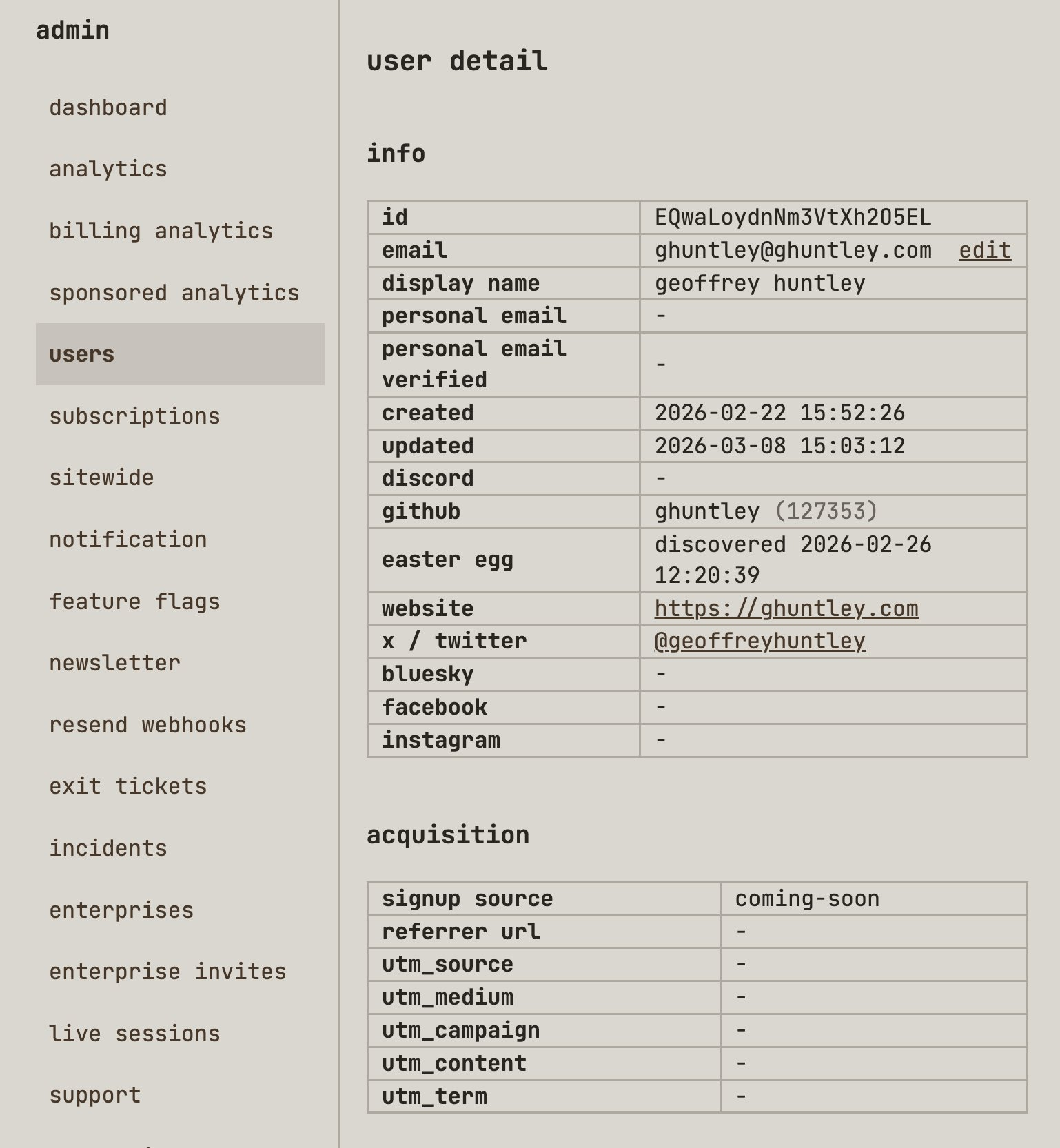
So let's pull up my own customer record and have a look at what's inside.
Seems pretty from vanilla, right? But do you notice the acquisition section? latentpatterns.com has first-party analytics built in and is horizontally and vertically integrated throughout the platform. To do this, I literally just ripped a fart into my coding harness and said,
"Hey, I want PostHog. Make it happen".
The 'coming-soon' UTM is my landing page. You see, LP has not launched yet. I'm building it out in the open and hitting the pavement in San Francisco, New York, and around the world to validate the business case and am doing steak-and-handshake deals to shape the product through conversations with prospective customers. Doing all the unscalable things. Instead of doing LLM outreach and sales automation that way, I'm doing it the old-fashioned way.
Once someone signs up via LinkedIn or provides information in the three fields above, they get registered as a customer within the database. That might seem quite vanilla, but it's anything but.
Through the usage of PDL, I can automatically step up who they are, where they work, any achievements they've had in life, and insights such as their likely salary or whether they have decision-making power to purchase. When you take this information and you throw it into a perplexity search, you get this...
0:00
/0:06
This is baseline functionality that every business needs, and it needs to be first-party within their application. By having all this first-party data in my data tables, I can then layer agents on top of it to automatically prioritise my day via an agentic personal assistant.
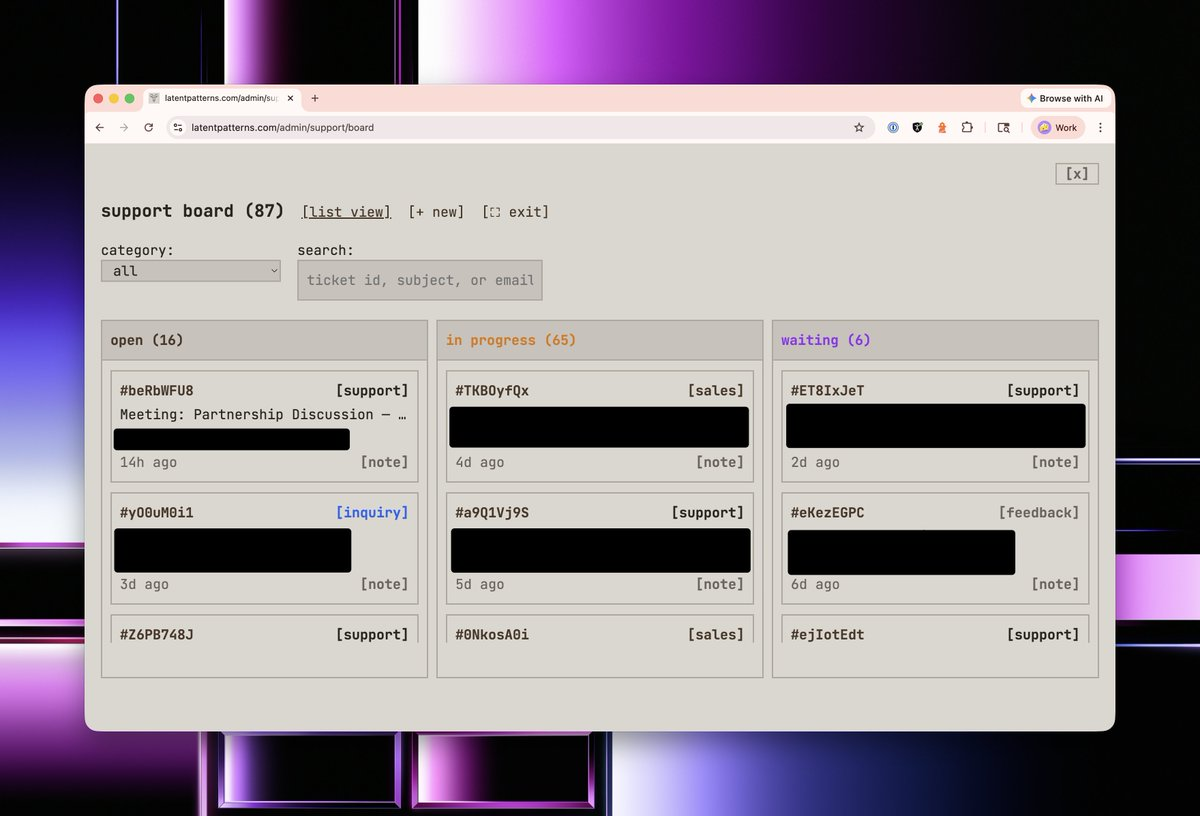
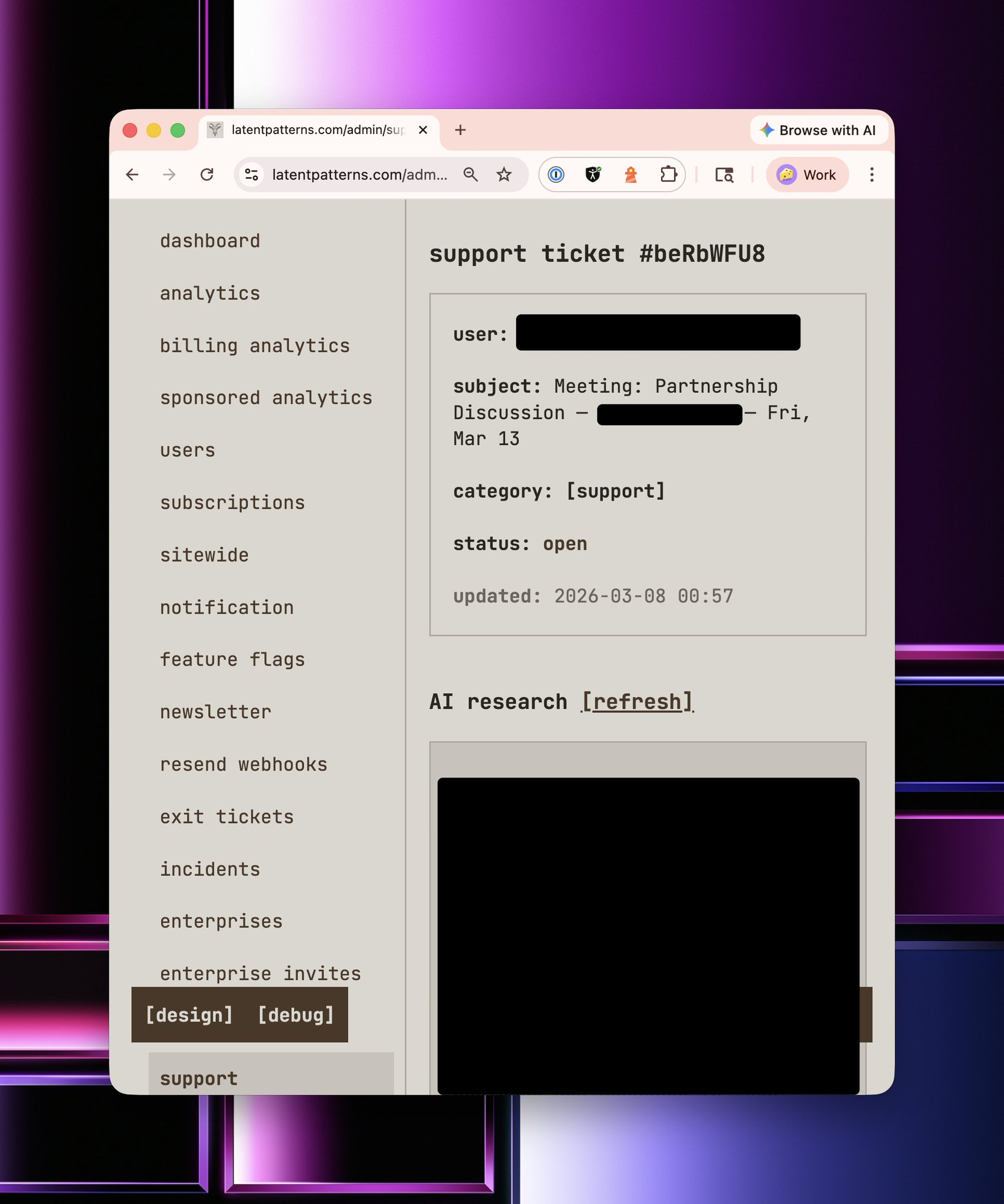
The next thing every business needs is a support desk and a customer relationship management tool. Classically, in most companies today, these are two separate things, and you have to build workflow automations to keep them in sync. No. In LP, they are a first-party thing, and they were built by ripping another fart into my coding agent, asking for
"Hey, I want PipeDrive, Trello, and ZenDesk"
On top of every customer interaction, the analysis is top and centre. It is deliberately there because it forces me to read this information again before I interact with the customer. This information is automatically refreshed by a background job every night.
Underneath this summary, for similar reasons, is also another summary of all the activity this person has done if they're in my Discord community (below)
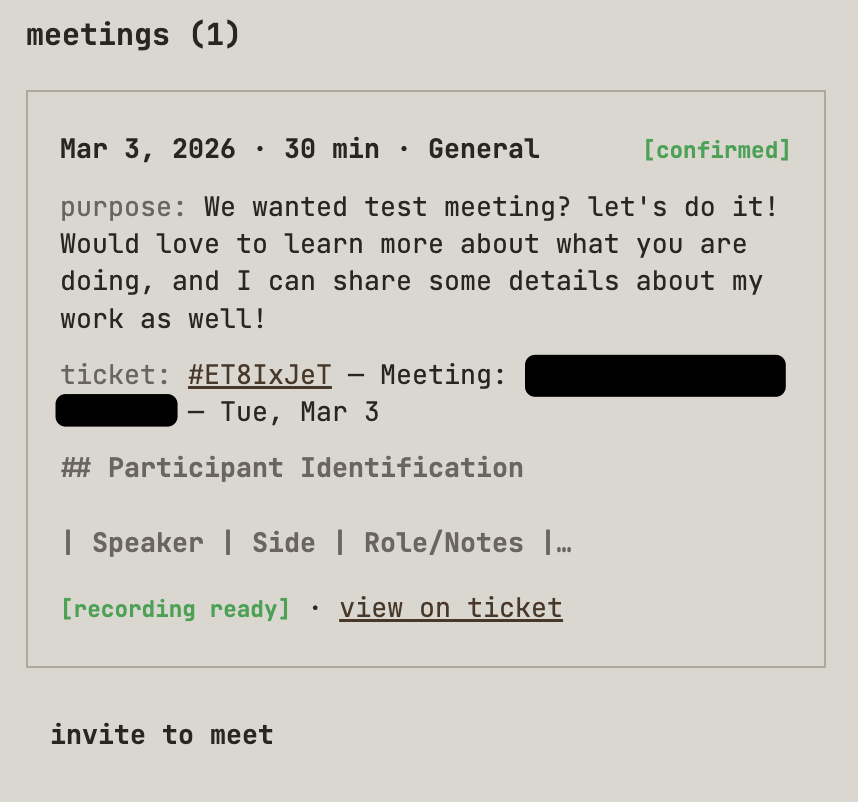
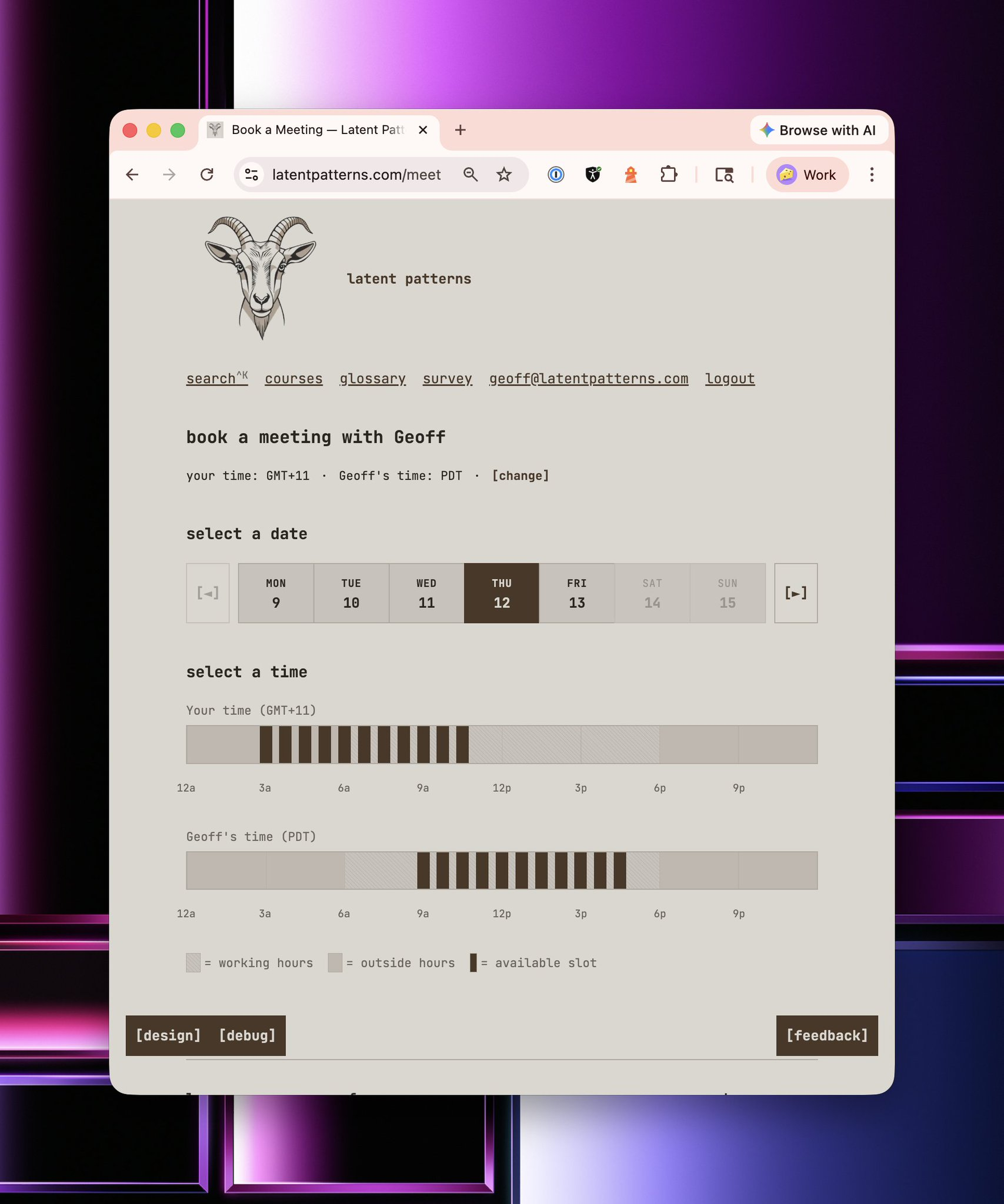
Then, finally, before I even get to the support desk ticket, I have to scroll past and review all the meetings I've had with the person. You see, beans, beans, the magical fruits, the more you eat, the more you toot. So ripped another fart into my coding harness, and I asked it to clone Calendly...
Throughout the website, various marketing funnels generate support desk tickets and offer the option to meet with me.
The calendar integration does exactly what you think it does, but with some twists. You see, the beans just keep on producing brain farts, so I prompted my way to victory and made my very own meeting transcription bot that automatically joins these meetings and asks for consent to take notes and record the meeting.
At the end of the meeting, I rip an agent over the transcription and apply sales automation using a mixture of Challenger-based sales and SPIN Selling as a series of LLM prompts. You see, in a previous life, I was also a sales engineer. Items captured include:
Competitive Landscape
Budget & Approval Process
Seat Sizing & Expansion Potential
Reseller & Training Partner Potential
Signals & Sentiment
Buying signals
Champion indicators
Rapport notes
Information Gaps
Decisions Made
Follow-Up Items
Product Demo (What was shown, Questions They Asked)
Content Interest & Feature Requests
Perception of the product demo
Pain Points & Needs
From there, it's just not so easy, but it's a skill that you can learn. Shut up and become curious. When someone says something, just ask why they said it.
All you need to do is get folks talking, and the more they share about their needs and pain points, the more information the LLM prompts can process. The more data you can gather, the more effective the follow-up meetings, especially if it's an initial meeting. And with that data, you can then rip an agent over the top of it to do more business automation.
Thanks for reading, folks. I hope you enjoyed this sneak preview. I'm going all in and building an educational platform. I'm living, breathing, and teaching what it means to be a model-first company. I'm building with recursive latent space, teaching it from my experiences as a one-man company.
just in case you missed my previous article about the unhinged things that you can now do as a model first company and why AI adoption will be a problem for corporates.
Latent Patterns is an educational platform for learning AI concepts. No fluff, no filler. Just the concepts you need, explained clearly.
I will be launching shortly. If you want to know when I launch, leave your digits here, or if you're a company interested in discussing employee education, fill in this form.
I'll be in SF for Daytona's event tomorrow and hanging around until Wednesday night, and then heading to New York. I'll be in New York for a week, then I'm heading to Auckland, Lithuania, Estonia, Sydney, Miami, Washington, DC, back to SF, then onwards to Singapore, Melbourne, Copenhagen, and Croatia. It's about 95 days of back-to-back travel. Cya ya'll all soon? ❤️
When Eelco Dolstra, father of Nix, descended from the mountain tops and enlightened us all, one of the main commandments for Nix was to eschew all uses of the Filesystem Hierarchy Standard (FHS).
The FHS is the “find libraries and files by convention” dogma Nix abandons in the pursuit of purity.
What if I told you that was a lie ? 😑
Nix was explicitly designed to eliminate standard FHS paths (like /usr/lib or /lib64) to guarantee reproducibility. However, graphics drivers represent a hard boundary between user-space and kernel-space.
The user-space library (libGL.so) must match the host OS’s kernel module and the physical GPU.
Nearly all derivations do not bundle libGL.so with them because they have no way of predicting the hardware or host kernel the binary will run on.
What about NixOS? Surely, we know what kernel and drivers we have there!? 🤔
Well, if we modified every derivation to include the correct libGL.so it would cause massive rebuilds for every user and make the NixOS cache effectively useless.
To solve this, NixOS & Home Manager introduce an intentional impurity, a global path at /run/opengl-driver/lib where derivations expect to find libGL.so.
We’ve just re-introduced a convention path à la FHS. 🫠
Unfortunately, that leaves users who use Nix on other Linux distributions in a bad state which is documented in issue#9415, that has been opened since 2015. If you tried to install and run any Nix application that requires graphics, you’ll be hit with the exact error message Nix was designed to thwart:
error while loading shared libraries: libGL.so.1:
cannot open shared object file: No such file or directory
There are a couple of workarounds for those of us who use Nix on alternate distributions:
nixGL, a runtime script that injects the library via $LD_LIBRARY_PATH
manually hacking $LD_LIBRARY_PATH
creating your own /run/opengl-driver and symlinking it with the drivers from /usr/lib/x86_64-linux-gnu
For those of us though who cling to the beautiful purity of Nix however it feels like a sad but ultimately necessary trade-off.
Thou shall not use FHS, unless you really need to.
Hey folks, the last year I've been pondering about this and doing game theory around the discovery of Ralph, how good the models are getting and how that's going to intersect with society. What follows is a cold, stark write-up of how I think it's going to go down.
The financial impacts are already unfolding. Back when Ralph started to go really viral, there was a private equity firm that was previously long on Atlassian and went deliberately short on Atlassian because of Ralph. In the last couple of days, they released their new investor report, and they made absolute bank.
I discovered Ralph almost a year ago today, and when I made that discovery, I sat on it for a while and focused on education and teaching juniors to pay attention and just writing prolifically, just writing and doing keynotes internationally, pleading with people to pay attention and to invest in themselves.
It's now one year later, and the cost of software development is $10.42 an hour, which is less than minimum wage and a burger flipper at macca's gets paid more than that. What does it mean to be a software developer when everyone in the world can develop software? Just two nights ago, I was at a Cursor meetup, and nearly everyone in the room was not a software developer, showing off their latest and greatest creations.
Well, they just became software developers because Cursor enabled them to become one. You see, the knowledge and skill of being a software developer has been commoditised. If everyone can be a software developer, what does that mean if your identity function is that you're a software developer and you write software for a living?
My theory of how it all goes down and gets feral really, really fast. Is quite simple...
For the past month, I've been catching up with venture capitalists in Australia and San Francisco and rubber-ducking this concept. You see, for a lot of them, they're not even sure whether their business model as venture capitalists still exists.
Why does someone need to raise a large amount of capital if it's just five man show now?
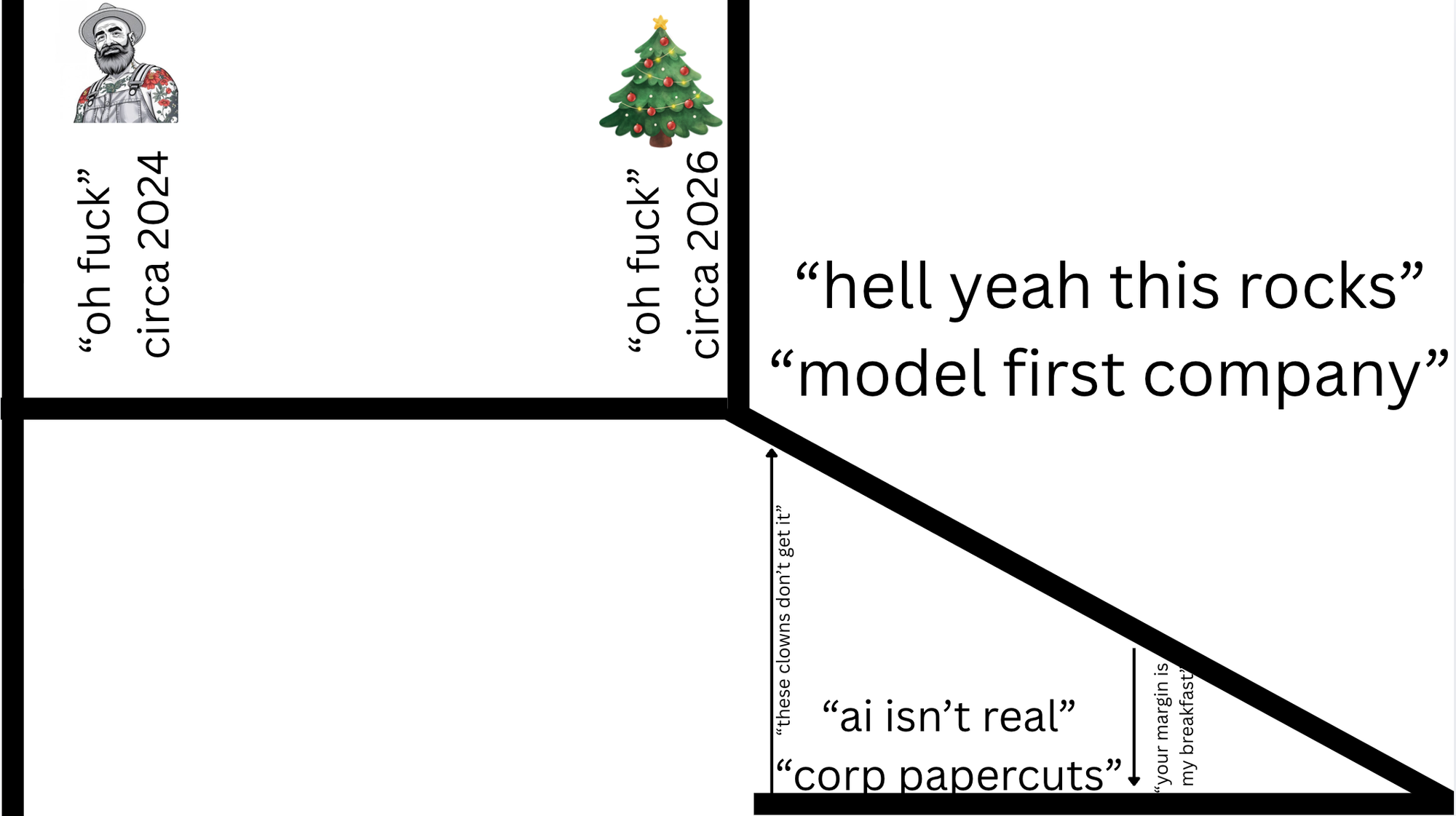
So let's open up with a classic K shape.
We rewind time to Christmas two years ago, where I originally posted, An "oh fuck" moment in time it was clear to me where this was going. The models were already good enough back then to cause societal disruption. The models were pretty wild; like wild horses, and they needed quite a great deal of skill to get outcomes from them...
If we fast-forward to the last Christmas holidays, many people had their "oh fuck" moment a year later, and the difference between now and then is twofold.
One: they actually picked up the guitar, played it, and took the Christmas period off because they had the space, capacity, and time to invest in themselves and make discoveries.
Two, the horses or models came with factory defaults of "broken in and ready to get shit done", which made them more accessible; they're easier to use to achieve outcomes, so people didn't need to invest as much time learning how to juice them to get disruptive outcomes.
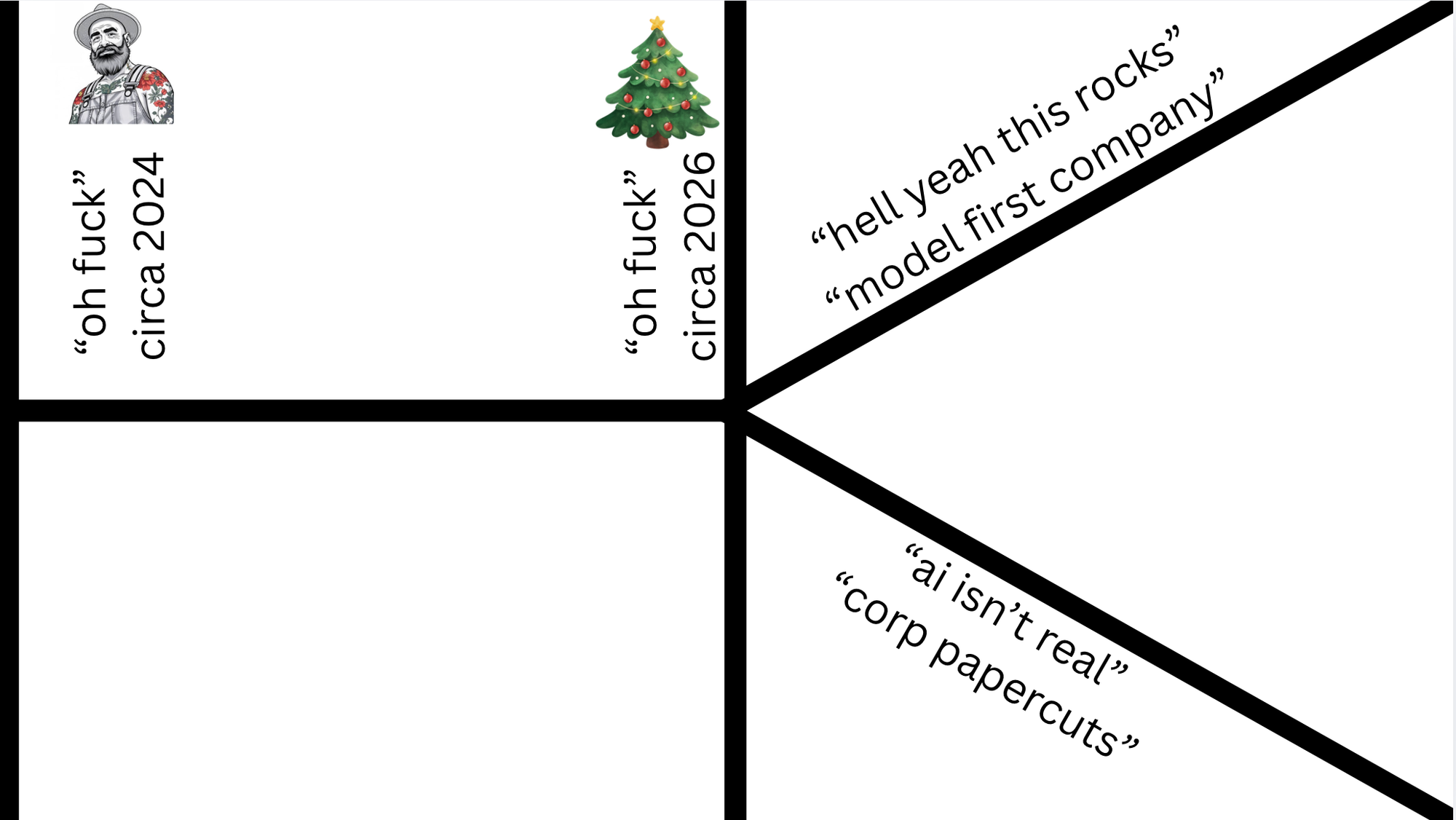
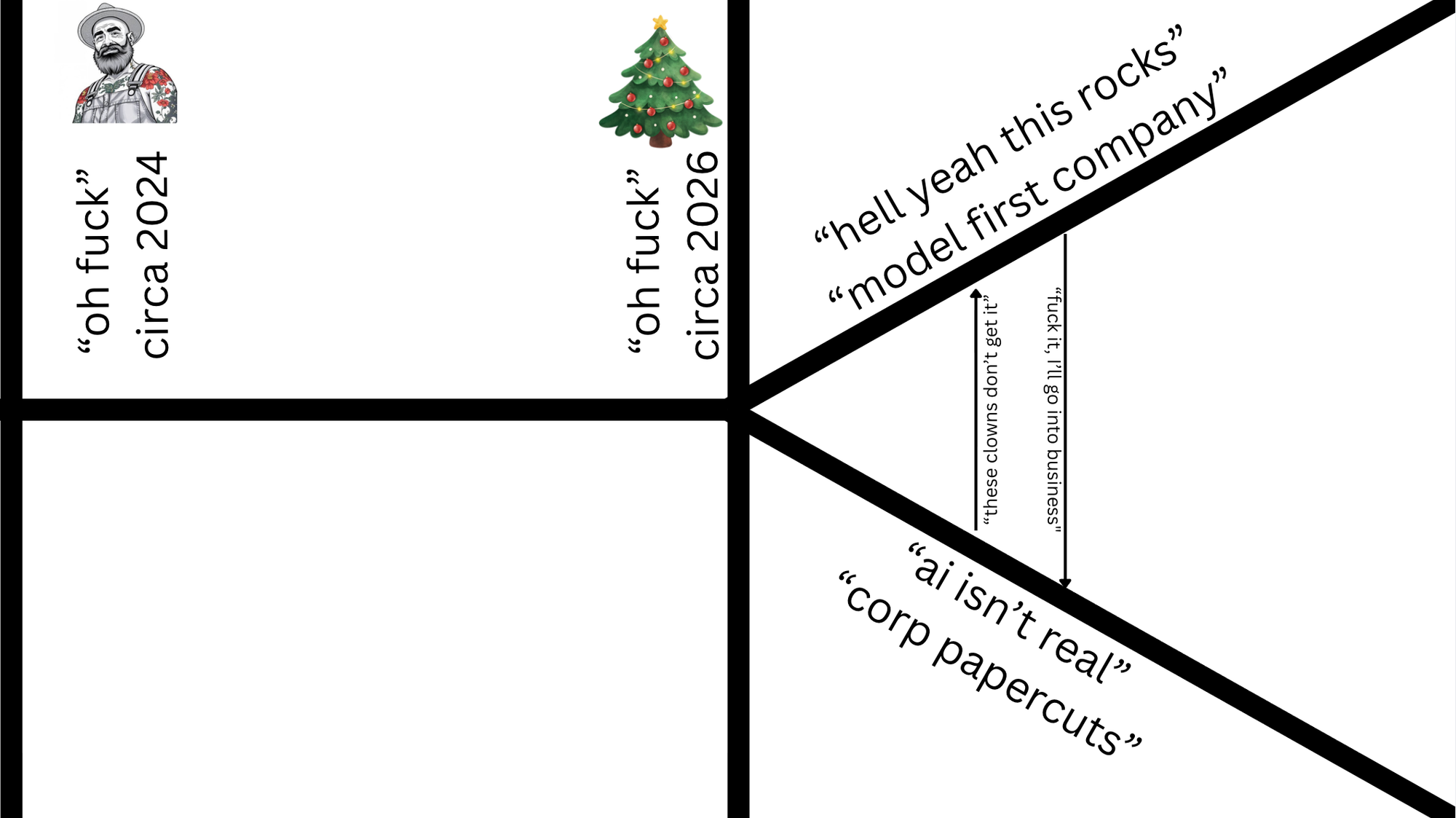
The world is now divided into two types of companies. Model first companies that are lean, apex predators who can operate on razor-thin margins and crush incumbents.
The next side of the equation is nearly every company out there today, which needs to go through a people transformation program, figure out what to do with AI, and deal with the fact that the fundamentals of business have changed.
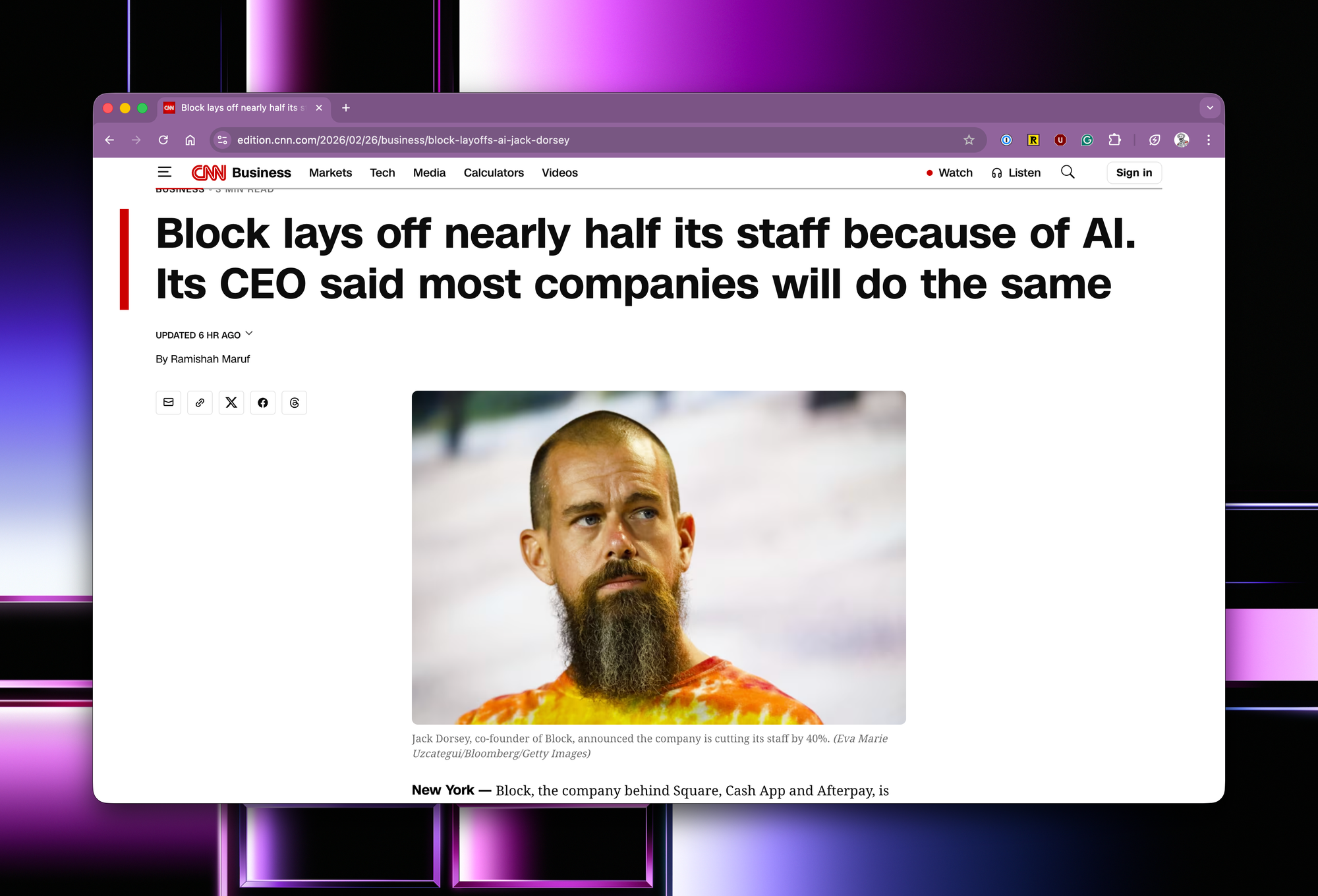
Jack is doing the right thing for his company by acting early. What will happen is that the time for a competitor to be at your door will be measured in months, not years. And as models get better, the timeframe only compresses.
The real question is for the folks who, unfortunately, were laid off today; they will need jobs, and they will now see the importance of upskilling with AI. So they'll go on to their next employer or other industries and upskill with AI, and then seek to implement what is needed - automating job functions via AI.
Then the cycle continues across all industries, all disciplines.
But it's not going to be just triggered by layoffs. It'll be just triggered by executives who don't get it. When you understand what is going on and how real AI is, it is maddening to be in a company surrounded by people who don't get it.
tfw when Canva's CTO puts you on full blast 😎
[ps. that 50k LOC is on all endpoints and uplifts devs+non-devs usage of AI and is single source of truth for MCP at Canva] pic.twitter.com/E19pyd9meZ
You see, there is a difference between business suicide and employment suicide. The smart folks who don't want to commit employment suicide will leave.
I've never seen this before in my career: 28-30 year olds who refuse to use AI coding tools.
You show them what they can do augmented (not replaced) with AI and you see in their eyes that they have no damn clue of what's happening.
The smarter ones in that segment will just go and found their own companies, then come back and do what they know. And they'll attack their employers vertically, operating leaner and meaner.
As the models get better, which is slope on slope derivative pace at this stage and as model-first companies get better and better and better at automating their job function, they can be at the door of their previous employer in months, not years.
To make matters worse, as the models get better, time gets compressed, and the snake eating its tail speeds up.
Which results in employers who did not take corrective actions, unlike Jack, having to lay off people in the long run because margins are being squeezed by new competitors operating leaner, meaner, and faster.
Then the cycle continues across all industries, all disciplines.
As I've been stressing in my writing for almost a year now, employers and employees trade time and skill for money. If a company is having problems adopting AI, then that is a company issue, not an employee issue.
Experience as a software engineer today doesn’t guarantee relevance tomorrow. The dynamics of employment are changing: employees trade time and skills for money, but employers’ expectations are evolving rapidly. Some companies are adapting faster than others.
Another thing I've been thinking: when someone says, “AI doesn’t work for me,” what do they mean? Are they referring to concerns related to AI in the workplace or personal experiments on greenfield projects that don't have these concerns?
This distinction matters.
Employees trade skills for employability, and failing to upskill in AI could jeopardise their future. I’m deeply concerned about this.
If a company struggles with AI adoption, that’s a solvable problem - it's now my literal job. But I worry more about employees.
In history, there are tales of employees departing companies that resisted cloud adoption to keep their skills competitive.
The same applies to AI. Companies that lag risk losing talent who prioritise skill relevance.
Model weight first companies should be scaring the fuck out of every founder right now if they're not a utility service, for what is a moat now in the era when you can /z80 something?
On the topic of moats, I've been thinking about this for almost a year now, and I think I've now got a clearer sense of what moats are in the AI era, but first, let's talk about what moats aren't...
Any business model that's based on per-seat pricing, as AI starts to rip harder and harder, is going to become much harder to maintain headcount within a corporation because model-first companies will be coming into business and operating much leaner using utility-based pricing. It's a margin game now.
Any product features or platforms that were designed for humans. I know that's going to sound really wild, but understand these days I go window-shopping on SaaS companies' websites for product features, rip a screenshot into Claude Code, and it rebuilds that product feature/platform. As we enter the era of hyper-personalised software, I think this will be the case more and more. In my latest creation, I have cloned Posthog, Jira, Pipedrive, and Calendly, and the list just keeps on growing because I want to build a hyper-personalised business that meets all my needs, with full control and everything first-party. I think we're going to see more and more of model first companies operating with this mindset.
Any business thought that revolved around the high cost of switching from one technology to another, or migrations from one technology to another, was a form of lock-in. This is provably falsified now. It is so easy to rip a fart into Claude Code and migrate from one technology to another. Just last week, I migrated from Cloudflare D1 to a PlanetScale Postgres database automatically using a Ralph Loop, and it just worked. Full-on data migration. When have you ever heard of a database migration going successfully unattended? We're here now, folks.
If you currently work at a company that fits the top three bullet points, then understand that things are going to get really tight at your employer. I don't know when, but with certainty it will happen. Your best choices are either to find a new employer if the people around you don't get it, or, if there is a need and desire for automation, to lean so hard into AI, automate everything, and become the champion of AI within your company. If your company has banned AI outright, you need to depart right now and find another employer.
So with that out of the way, what is a moat?
Distribution. Any form of distribution. Brand awareness. Steaks and handshakes.
Utility-based pricing, similar to cloud infrastructure on a cents per megabyte or CPU hour.
Operating as a model-first company and accelerating the transformation so you can operate under the principles below:
AI erases traditional developer identities—backend, frontend, Ruby, or Node.js. Anyone can now perform these roles, creating emotional challenges for specialists with decades of experience. - https://ghuntley.com/six-month-recap
This is going to be a really hard time for a lot of people because identity functions have been erased, and the hard thing is, it's not just software developers. It's people managers as well. If your identity function is managing people, you need to make adjustments. You need to get back onto the tools ASAP.
Were smaller but effectively cut 2/3rds by telling board I wouldn’t backfill in May 2023. Best decision as got rid of all the people who “are sick of hearing about ai”. 20ish people now do about 30x the output of what having more than 60 did 3 years ago. - an anonymous founder in my DMs today.
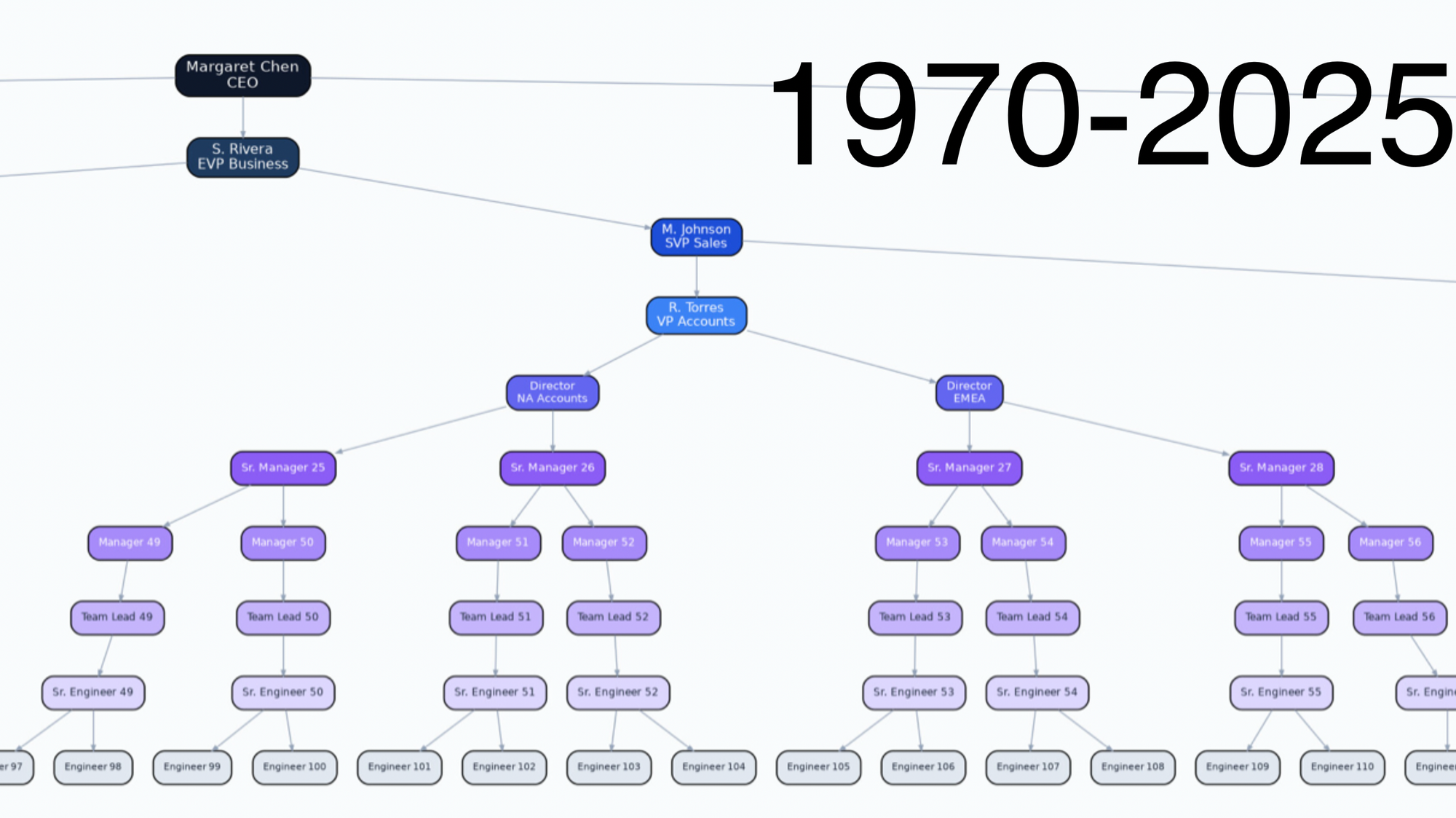
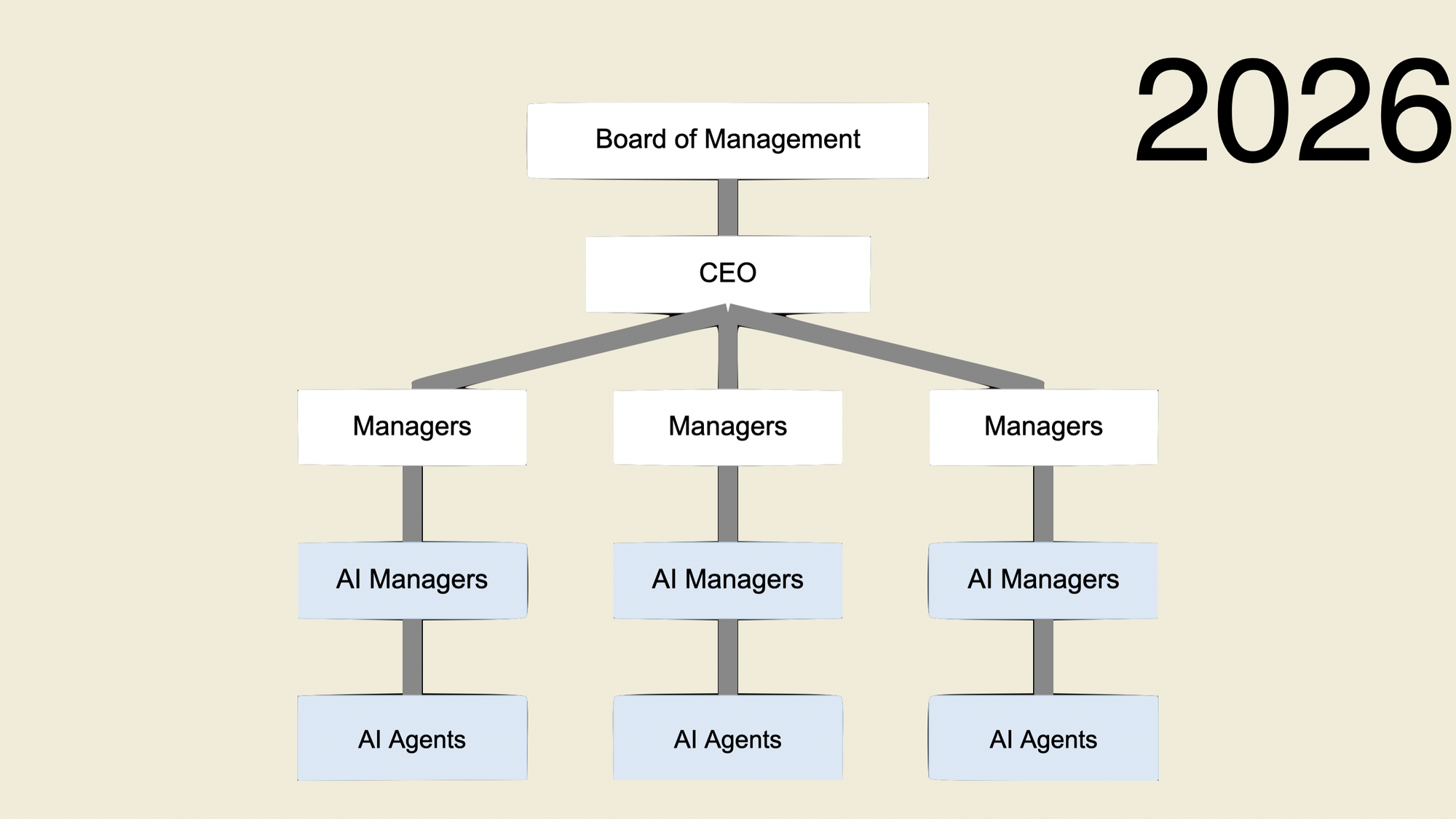
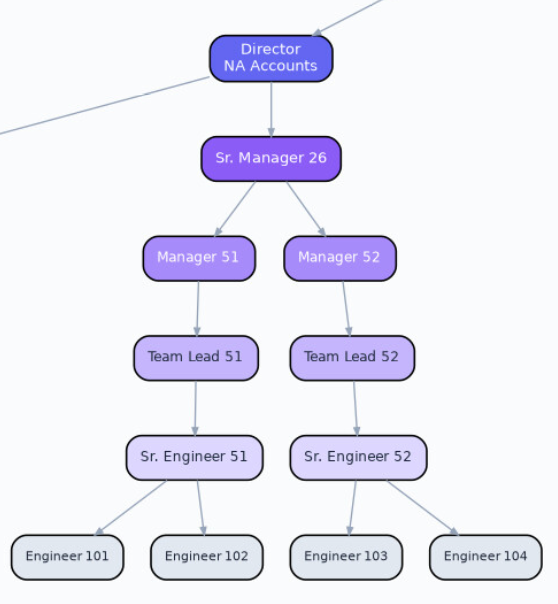
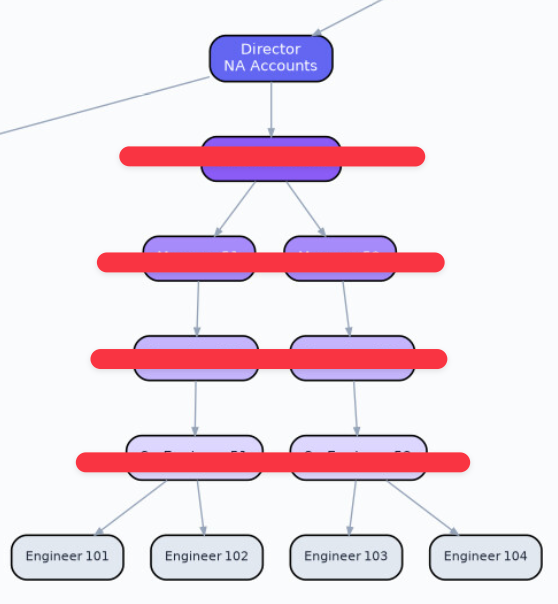
This transformation is going to be brutal. Organisations need to be designed differently and need to transform from this...
to this...
And one of the hardest things is that AI is being rammed into the world non-consentually. It's been pushed by employers and Silicon Valley. Yeah, it sucks, but you gotta pull your chin up, process those feelings and deal with it, but for others it's gonna be really, really rough. There are going to be people who have spent years of their lives doing Game of Thrones, social political stuff, to get to where they are within a company, and it will have been all for nothing.
In the org chart above, consider what the value of the senior engineer, the team lead, the manager and the senior manager in this brave new world is? How much time is spent doing Dilbert activities? What if you can flatten the org chart? If you were a founder, why wouldn't you?
This is what I've been fearing for a year. I could be wrong, I don't know. Anyone who says that they know for sure is selling horseshit. One thing is absolutely certain: things will change, and there's no going back. The unit economics of business have forever changed.
Wait so you're telling me
Solo builders are running entire companies now with AI employees working 24/7
While traditional teams are still stuck in the "we need more headcount" meeting
Whether a company does layoffs really comes down to the quality of its leadership. If they're being lazy and don't have ambitious plans, they will need to lay off, because eventually the backlog will run dry, and everything will get automated.
This isn't me throwing shit at Jack. Like, literally, it's a cold, hard fact that you need fewer people to run a business now. So if you have too many people on your payroll, you need to make changes, but having said that, there will be ambitious founders and leaders who didn't overhire and understand that AI enables them to do anything, and they can do it today. They can make that five-year roadmap happen in a year and provide a backlog for all employees to work on while they utilise AI.
It's going to be really interesting to see how this pans out.
All I can ask you to do is tap someone else on the shoulder and stress to them to treat this topic seriously, upskill, and explain the risks going forward, and then ask them to do the same. You see, for a lot of people, they haven't noticed AI is knocking on their door because AI is burrowing under their house.
For about 9 years, I’ve been a customer of Google G-Suite, using it
for email, file storage, and photos. I’ve never fully trusted them,
however I have always claimed the following.
As a paying customer, I hope that they mine my data less than they
do for free users.
There’s a lot of uncertainty in that sentence. Words like hope and
less aren’t exactly reassuring, and there’s no proof it’s actually
the case either. With a recent price increase warning at renewal time
and the current state of politics between the EU and USA, I decided to
switch to an EU provider.
In a previous post, I wrote about linker relaxation: the linker’s ability to replace a slower, larger instruction with a faster, smaller one when it has enough information at link time. For instance, an indirect call through the GOT can be relaxed into a direct call plus a nop. This is a well-known technique to optimize the instructions for performance.
Does it ever make sense to go the other direction? 🤔
We’ve been working on linking some massive binaries that include Intel’s Math Kernel Library (MKL), a prebuilt static archive. MKL ships as object files compiled with the small code-model (mcmodel=small), meaning its instructions assume everything is reachable within ±2 GiB. The included object files also has some odd relocations where the addend is a very large negative number (>1GiB).
The calculation for the relocation value is S + A - P: the symbol address plus the addend minus the instruction address. WIth a sufficiently large negative addend, the relocation value can easily exceed the 2 GiB limit and the linker fails with relocation overflows.
We can’t recompile MKL (it’s a prebuilt proprietary archive), and we can’t simply switch everything to the large code model. What can we do? 🤔
I am calling this technique linker pessimization: the reverse of relaxation. Instead of shrinking an instruction, we expand one to tolerate a larger address space. 😈
The Problematic LEA
The specific instructions that overflow in our case are LEA (Load Effective Address) instructions.
In x86_64, lea r9, [rip + disp32] performs pure arithmetic: it computes RIP + disp32 and stores the result in r9 without accessing memory. The disp32 is a 32-bit signed integer embedded directly into the instruction encoding, and the linker fills it in via an R_X86_64_PC32 relocation.
The relocation formula is S + A - P. Let’s look at an example with a large addend.
Term
Meaning
Value (approximate)
S (Symbol)
Addfress of symbol
~200 MB into .rodata
A (Addend)
Constant baked into the object file
0x44000000 (−1,062 MB)
P (Position)
Address of the instruction being patched
~1,200 MB into .text
S + A - P = 200 + (−1062) − 1200
= −2062 MB
A 32-bit signed integer can only represent ±2,048 MB (±2 GiB). Our value of −2,062 MB exceeds that range and the linker rightfully complains 💥:
ld.lld: error: libfoo.a(...):(function ...: .text+0x...):
relocation R_X86_64_PC32 out of range:
-2160984064 is not in [-2147483648, 2147483647]
Note
These LEA instructions appear in MKL because the library uses them as a way to compute an address of a data table relative to the instruction pointer. The large negative addend (-0x44000000) is intentional; it’s an offset within a large lookup table.
The Idea: Replace LEA with MOV
The core idea is delightful because often as an engineer we are trained to optimize systems, but in this case we want the opposite. We swap the LEA for a MOV that reads through a nearby pointer.
Recall from the relaxation post: relaxation shrinks instructions (e.g. indirect call -> direct call). Here we do the opposite: we make the instruction do more work (pure arithmetic -> memory load) in exchange for a reachable displacement. That’s why I consider it a pessimization or reverse-relaxation.
Both instructions use the same encoding length (7 bytes with a REX prefix), so the patch is a single byte change in the opcode. 🤓
LEA: 4C 8D 0D xx xx xx xx lea r9, [rip + disp32] (opcode 0x8D)
MOV: 4C 8B 0D xx xx xx xx mov r9, [rip + disp32] (opcode 0x8B)
^^
only this byte changes!
The difference in behavior is critical:
LEA: r9 = RIP + disp32 (arithmetic, no memory access). disp32 must encode the entire distance to the far-away data. This overflows.
MOV: r9 = *(RIP + disp32) (memory load). disp32 points to a nearby 8-byte pointer slot. The pointer slot holds the full 64-bit address. This never overflows.
Visualizing the Change
Original — the LEA must reach across the entire binary:
disp32 must encode this entire distance
╭──────────────────────────────────────────╮
│ ~2+ GiB (OVERFLOW!) │
│ │
.text ▼ │
┌──────────────────────────┐ │
│ lea r9, [rip + disp32] │─────────── X ────────────────┤
│ (0x8D) │ can't fit in 32 bits! │
└──────────────────────────┘ │
│
.rodata (far away) │
┌──────────────────────────┐ │
│ symbol + offset │◄─────────────────────────────╯
└──────────────────────────┘
Pessimized — the MOV reads a nearby pointer that holds the full address:
We’ve traded one direct LEA computation for an indirect MOV through a pointer, and we make sure the displacement is now tiny. The 64-bit pointer slot can reach any address in the virtual address space. 👌
Implementation Details
For each problematic relocation, three changes are needed in the object file:
1. Opcode Patch: In .text, change byte 0x8D to 0x8B (1 byte).
This converts the LEA (compute address) into a MOV (load from address). The rest of the instruction encoding (ModR/M byte, REX prefix) stays identical because both instructions use the same operand format.
Before: 4C 8D 0D xx xx xx xx lea r9, [rip + disp32]
After: 4C 8B 0D xx xx xx xx mov r9, QWORD PTR [rip + disp32]
^^
2. New Pointer Slot — Create a new section (.data.fixup) containing 8 zero bytes per patch site, plus a new R_X86_64_64 relocation pointing to the original symbol with the original addend.
R_X86_64_64 is a 64-bit absolute relocation. Its formula is simply S + A, no subtraction of P. There is no 32-bit range limitation; it can address the entire 64-bit address space. This is the key insight that makes the fix work.
3. Retarget the Original Relocation — In the .rela.text entry for the patched instruction, change the symbol to point at the new pointer slot in .data.fixup and update the type to R_X86_64_PC32. The addend becomes a small offset (the distance from the instruction to the fixup slot), which is guaranteed to fit.
Note
Because both LEA and MOV with a [rip + disp32] operand are exactly the same length (7 bytes with a REX prefix), we don’t shift any code, don’t invalidate any other relocations, and don’t need to rewrite any other parts of the object file. It’s truly a surgical patch.
The pessimized MOV now performs a memory load where the original LEA did pure register arithmetic. That’s an extra cache line fetch and a data dependency. If this instruction is in a tight loop, it could be a performance hit.
Optimization is the root of all evil, what does that make pessimization? 🧌
I was writing a test case for lld to support “thunks” [llvm#180266] which uses a linker script to place two sections very far apart (8GiB) in the virtual address space.
8 GiB. For what amounts to a handful of instructions. 😲
What’s going on? And where did all that space come from?
Apparent size vs. on-disk size
Turns out ls -l reports the logical (apparent) size of the file, which is simply an integer stored in the inode metadata. It represents the offset of the last byte written. Since .text_high lives at 0x200000000 (~8 GiB), the file’s logical size extends out that far even though the actual code is tiny.
The real story is told by du:
$du-h output
12K output
12 KiB on disk. The file is sparse. 🤓
What is a sparse file?
A sparse file is one where the filesystem doesn’t bother allocating blocks for regions that are all zeros. The filesystem (ext4, btrfs, etc.) stores a mapping of logical file offsets to physical disk blocks in the inode’s extent tree. For a sparse file, there are simply no extents for the hole regions.
For our 8 GiB binary, the extent tree looks something like:
Inode extent tree:
[offset 0, 12 blocks] → disk blocks 48392-48403 (.text_low code)
[offset 0x1FFFF, 4 blocks] → disk blocks 48404-48407 (.text_high code)
(nothing for the ~8 GiB in between — no extents exist)
We can use filefrag to also see the same information, albeit a little more condensed.
$defrag -v output
Filesystem type is: 9123683e
File size of output is 8589873896 (2097138 blocks of 4096 bytes)
ext: logical_offset: physical_offset: length: expected: flags:
0: 0.. 1: 461921719.. 461921720: 2: encoded
1: 2097137.. 2097137: 461921740.. 461921740: 1: 464018856: last,eof
output: 2 extents found
When something reads the file:
The virtual filesystem (VFS) receives read(fd, buf, size) at some offset
The filesystem looks up the extent tree for that offset
If extent found then read from the physical disk block
If no extent (hole) then the kernel fills the buffer with zeros, no disk I/O
Creating sparse files yourself
You don’t need a linker to create sparse files. truncate will do it:
I'm going to make this a really quick one because this is doing the rounds, and whilst I've tweeted about it, it's time to dig in.
Pragmatic Engineer's @GergelyOrosz is on a "secret email list" of agentic AI coders, and they're starting to report trouble sleeping because agent swarms are "like a vampire."
"A lot of people who are in 'multiple agents mode,' they're napping during the day... It just really is… pic.twitter.com/slsPgCfkKw
What Gergely is articulating here is something that I and everyone else went through a year ago who were paying attention. AI enables you to teleport to the future and rob your future self of retirement projects. Anything that you've been putting off to do someday, you can do it now.
To quote a post I authored almost eight months ago:
It might surprise some folks, but I'm incredibly cynical when it comes to AI and what is possible; yet I keep an open mind. That said, two weeks ago, when I was in SFO, I discovered another thing that should not be possible.
Every time I find out something that works, which should not be possible, it pushes me further and further, making me think that we are already in post-AGI territory. - https://ghuntley.com/no/ (dated July 2025)
whereby that seventh stage is essentially this scene in the matrix...
In the previous 12 months, I've cloned SaaS product feature sets of many different companies. I've built file systems, networking protocols and even developed my own programming language.
From my perspective, nothing really changed in December. The models were already great, but what was needed was a time of rest - people just needed to pick up the guitar and play.
What makes December an inflection point was the models became much easier to use to achieve good outcomes and people picked up the guitar with an open mind and played.
Over the last couple of weeks, I've been catching up with software engineers, venture capitalists, business owners, and people in sales and marketing who are all going through this period of adjustment.
Universally, it can be described as a mild form of creative psychosis for people who like to create things. All builders who have an internal reward function of creating things as a form of pleasure go through it because AI enables them to just do things.
Everyone who gets AI goes through it, and it typically lasts about two to three months, until they get it out of their system by completing all the projects they were putting off until retirement.
Perhaps it could be described as a bit of a reset, similar to what happened during COVID-19, when people were able to reassess what they wanted to do in life.
It's a coin flip, really, because people are either going to commit more to their current employer if they are an employee, but on the other side of the coin, they're realising they are no longer dependent on others as much to achieve certain financial outcomes.
Perhaps this is the tipping point where more people throw their hats in and become entrepreneurs.
People with ideas and unique insight can get concepts to market in rapid time and be less dependent on needing others' expertise as the world's knowledge is now in the palms of everyone's hands.
Technologists are still required, perhaps it's the ideas guys/gals who should be concerned as software engineers now have a path to bootstrap a concept in every white collar industry (recruiting, law, finance, finance, accounting, et al) at breakneck speed without having to find co-founders.
- From Feb 2025
I guess I need to wrap this up now, but I will say this:
I've written about how some people won't make it, and I've spent the last year talking about this, pleading with people to pick up the guitar and play...
If you're having trouble sleeping because of all the things that you want to create, congratulations.
You've made it through to the other side of the chasm, and you are developing skills that employers in 2026 are expecting as a bare minimum.
The only question that remains is whether you are going to be a consumer of these tools or someone who understands them deeply and automates your job function?
go build yourself an agent and taste building in the recursive latent space
Trust me, you want to be in the latter camp because consumption is now the baseline for employment.
After you come out of this phase, I hope you get to where I am, because just because you can build something doesn't mean you necessarily should. Knowing what not to build now that anything can be built is a very important life lesson.
ps. socials
📰 What @GergelyOrosz is articulating here is something that I and everyone else went through a year ago who were paying attention. AI enables you to teleport to the future and rob your future self of retirement projects. Anything that you've been putting off to do someday, you… pic.twitter.com/OXm9VvXhdZ